March, 2024

Step 1: Import the relevant libraries
import tensorflow as tf
from tensorflow import keras
from keras.preprocessing.image import ImageDataGeneratorStep 2: Set the Number of metals/ alloys and their elemental compositions.
# Set a random seed for reproducibility; random seed ensures that the result of the random operations is reproducible
np.random.seed(42)
# Define base metals and alloying elements
base_metals = ['Cu', 'Fe', 'Al']
alloying_elements = ['Zn', 'C', 'Mg']
# Number of compositions to generate
n_compositions = 150Step 3: Let's generate 150 alloys/ compositions hypothetically. Consider Base metal % between 60 and 90 and the remaining % for the alloy element. Sum of base_element and alloy _element should be 100.
# create an empty list
compositions = []
for _ in range(n_compositions):
base_metal = np.random.choice(base_metals)
alloy_element = np.random.choice(alloying_elements)
# Randomly generate the percentage for the base metal and alloy element
base_percentage = np.random.randint(60, 91)
alloy_percentage = 100 - base_percentage
composition = f"{base_metal}-{base_percentage}%, {alloy_element}-{alloy_percentage}%"
compositions.append(composition)
# Example output
for i in range(5):
print(compositions[i])Output
Al-74%, Zn-26%
Al-80%, Zn-20%
Al-78%, C-22%
Al-70%, Mg-30%
Cu-81%, Mg-19%Step 4: Define Xs or Input features attributing to corrosion behaviour of 150 materials/ compositions
#Input variables considered are corrosion rate, corrosion density current, polarization resistance and media
np.random.seed(42)
metals_and_alloys = ['Metal/Alloy {}'.format(i) for i in range(1, n_compositions + 1)]
corrosion_rates = np.random.uniform(0.01, 0.5, size=n_compositions).round(3)
corrosion_density_currents = np.random.uniform(0.1, 10, size=n_compositions).round(2)
polarization_resistance = np.random.uniform(10, 10000, size=n_compositions).round(2)
media_options = ["Seawater", "Acidic Solution", "Alkaline Solution", "Sulfide Solution", "Atmospheric", "Oil & Gas Environment"]
media = np.random.choice(media_options, size=n_compositions)Step 5: Define target variable (y): Here we take corrosion resistance to categorize whether the metal/ alloys exhibits 'excellent', 'fair' or 'poor' corrosion property
# Define corrosion resistance based on corrosion rate
#Excellent: <= 0.15 mpy, Fair: > 0.15 and <= 0.3 mpy, Poor: > 0.3 mpy (mpy: mils per year)
corrosion_resistance = np.select( [corrosion_rates <= 0.15, corrosion_rates <= 0.3], ['Excellent', 'Fair'], default='Poor')Step 6: Create a Dataframe containing Xs and y
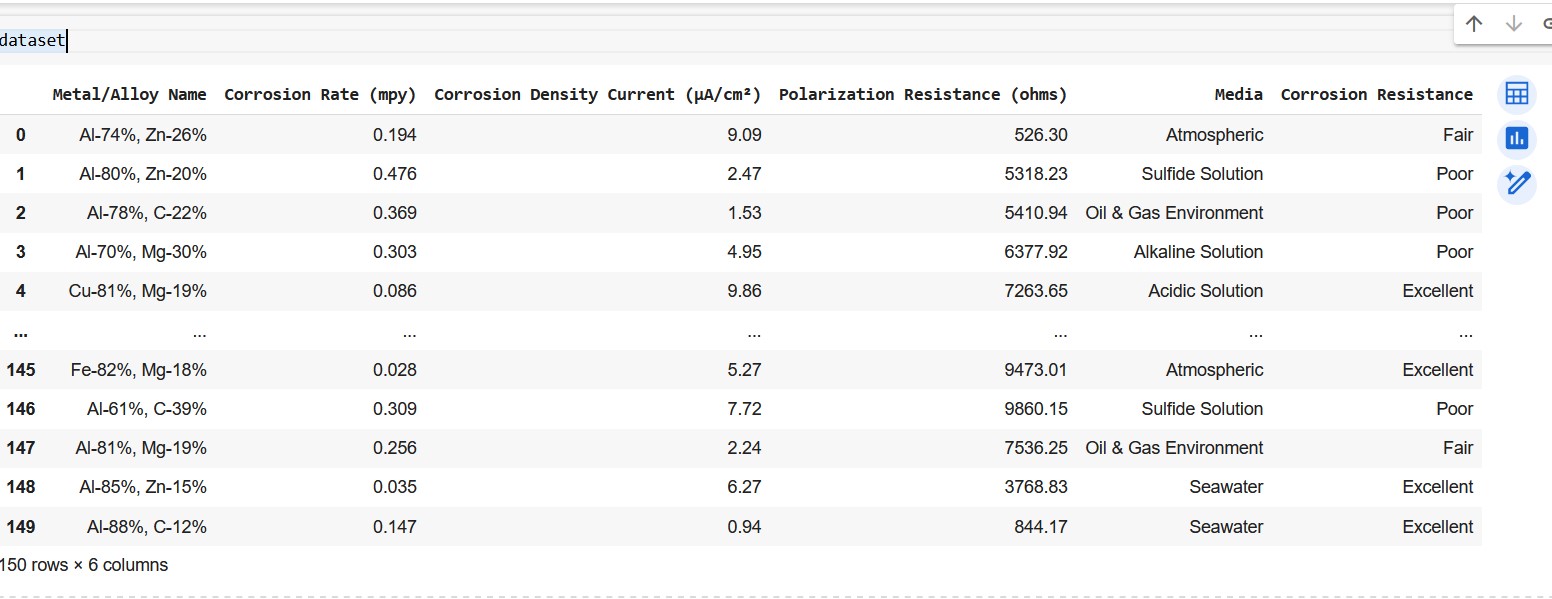
dataset = pd.DataFrame({ 'Metal/Alloy Name': compositions, 'Corrosion Rate (mpy)': corrosion_rates, 'Corrosion Density Current (µA/cm²)': corrosion_density_currents, 'Polarization Resistance (ohms)': polarization_resistance, 'Media': media, 'Corrosion Resistance': corrosion_resistance})Step 7: View the hypothetical dataset
datasetSnippet of the generated dataset
Export dataframe to csv and download the saved file to local computer.
dataset.to_csv('file1.csv')