April, 2024
Background
In my earlier tutorial, I have discussed the confusion matrix and its significance in understanding performance metrics for a machine learning model applied to a given dataset.
Here is a recap of a confusion matrix for binary classification.
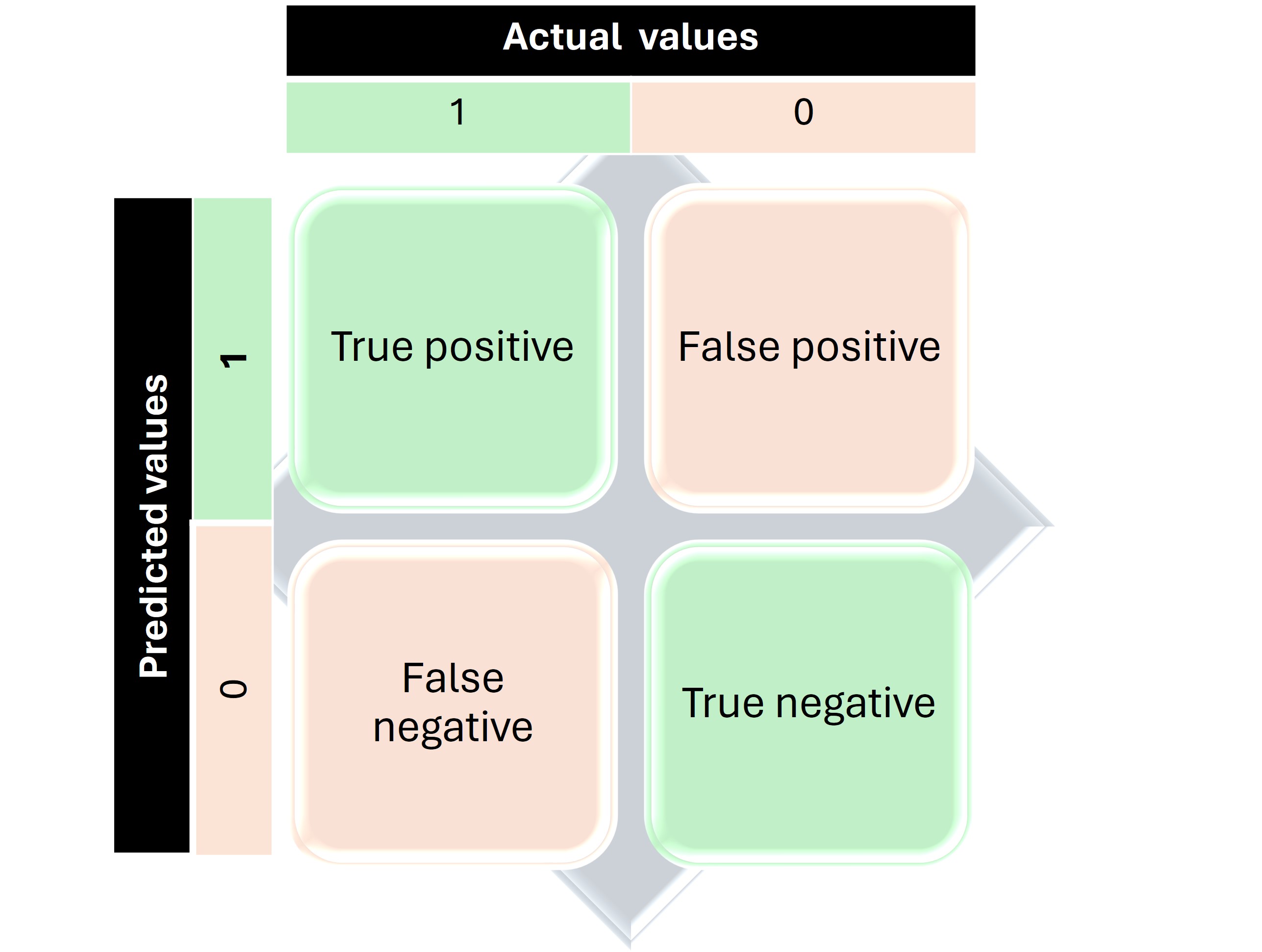
As the name suggests, binary classification results in a dichotomous outcome, such as 'yes' or 'no', 'present' or 'absent'. If the actual and predicted values coincide, the result is categorized as either a True Positive or a True Negative, depending on the presence or absence of the variable. Conversely, if the actual and predicted values do not match, the outcome is categorized as either a False Positive or a False Negative.
However, in real-world applications, we frequently encounter multiclass systems that offer a broader range of possible outcomes.
Let’s discuss how to read the confusion matrix accurately in these more complex scenarios.
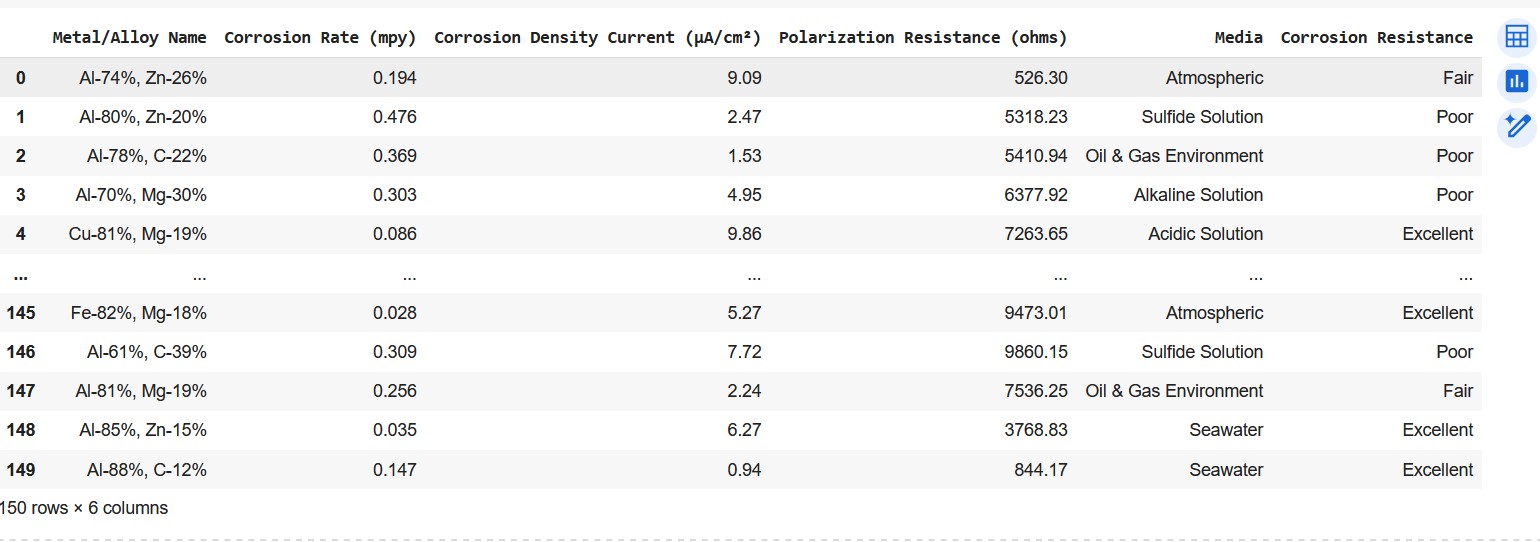
Let me take an example of a confusion matrix generated from a dataset capturing the corrosion properties of 150 metals and alloys. The snapshot of the dataset is displayed below for reference.The output variable,y (corrosion resistance) column has three outcomes: ‘Poor ’, ‘Fair’, and ‘Excellent’. The remaining columns are input variables (Xs).
The confusion matrix and the encoded categories are displayed below:
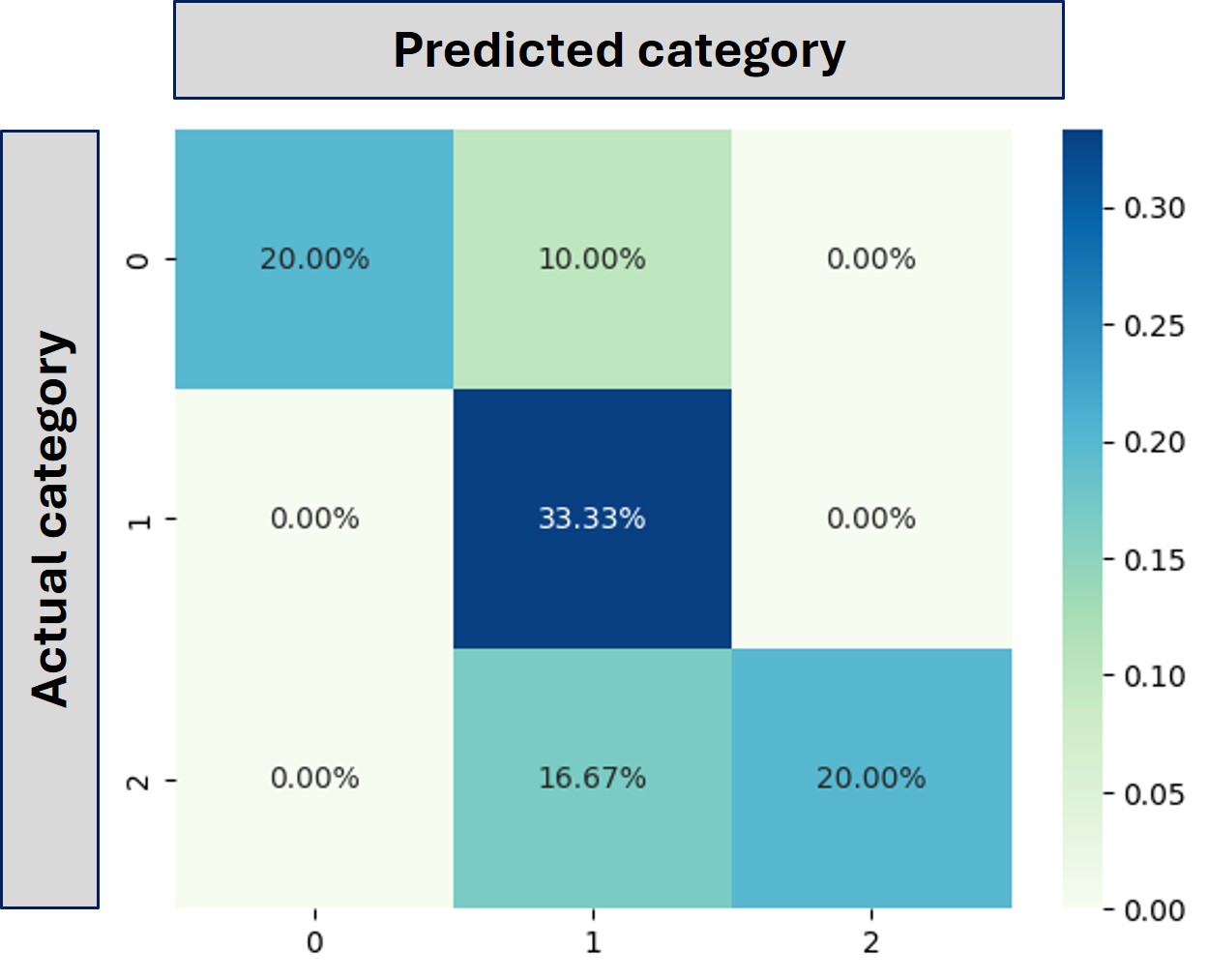

Let us start reading the above confusion matrix in steps.

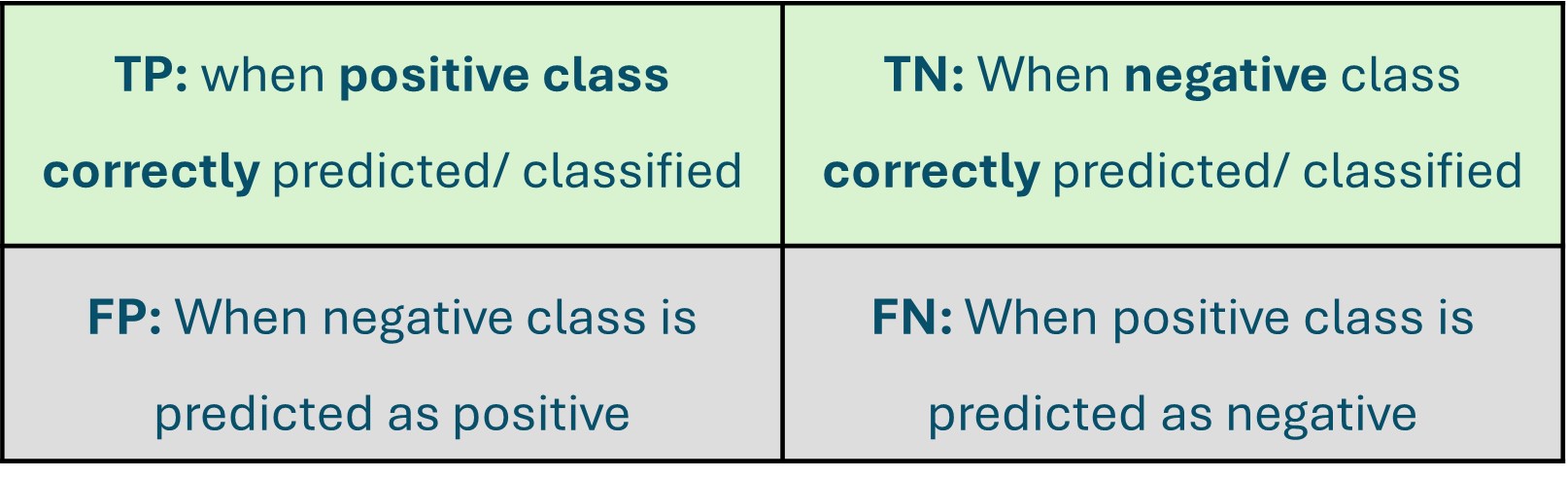
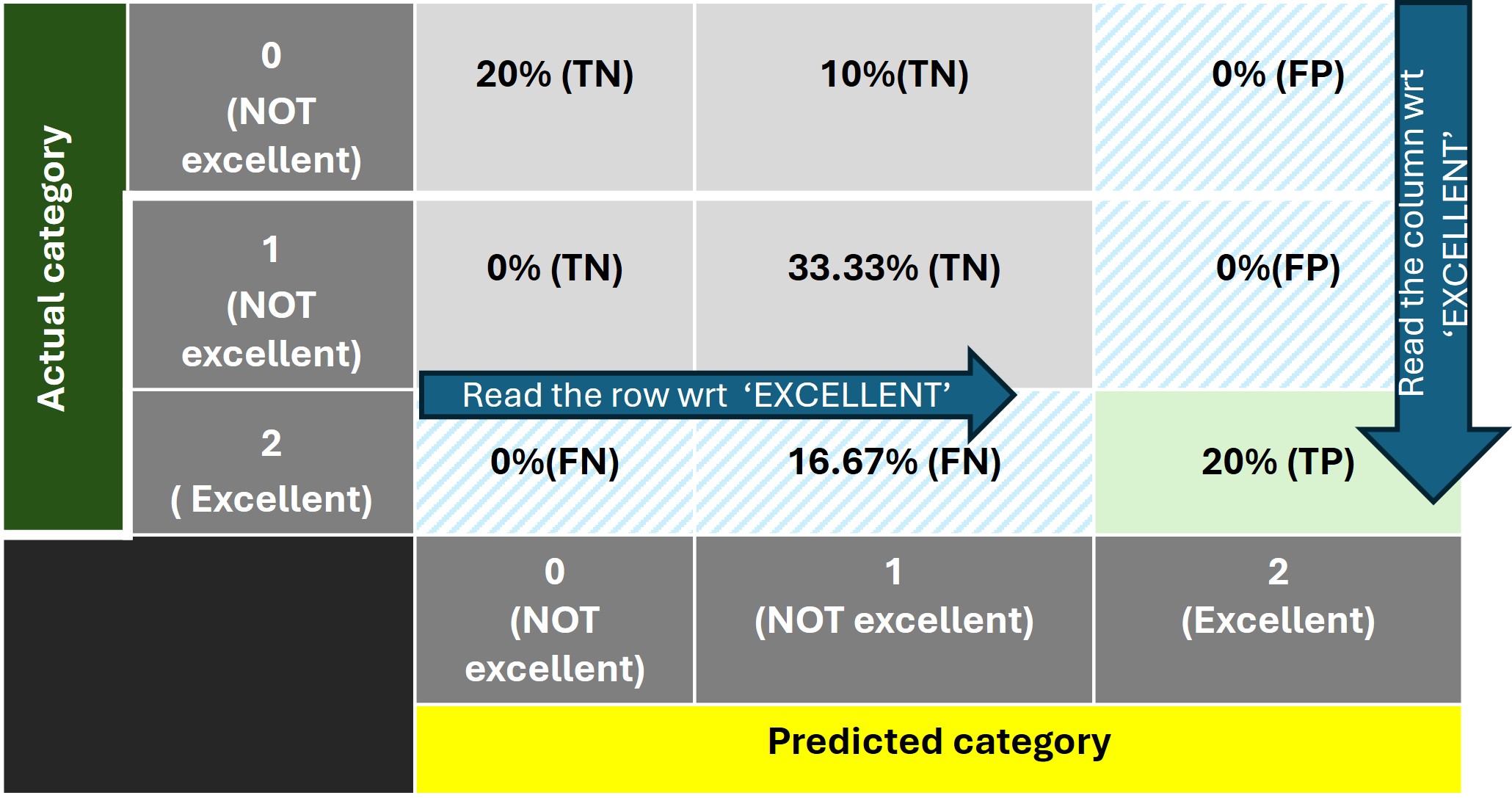
The confusion matrix for this category is shown below:
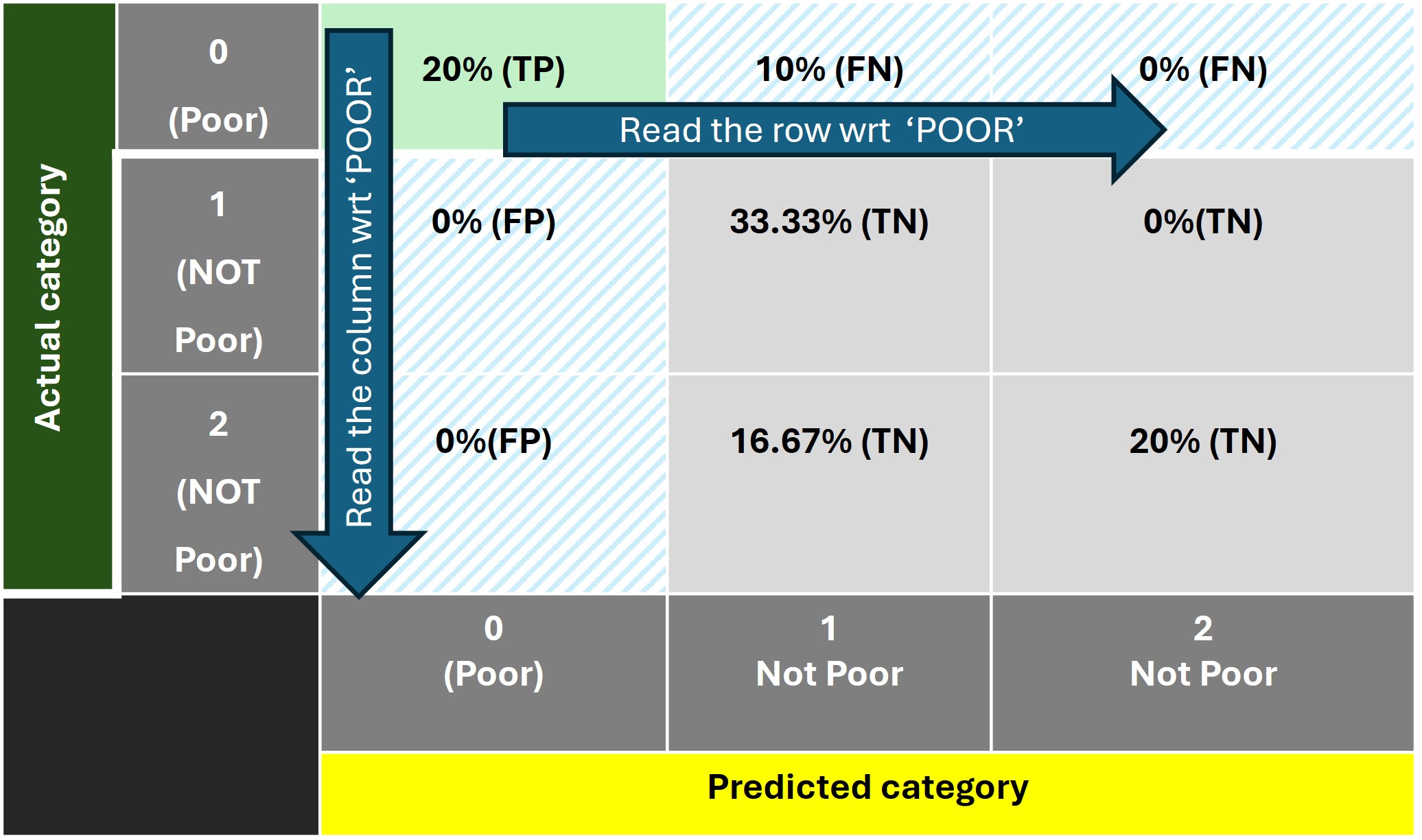
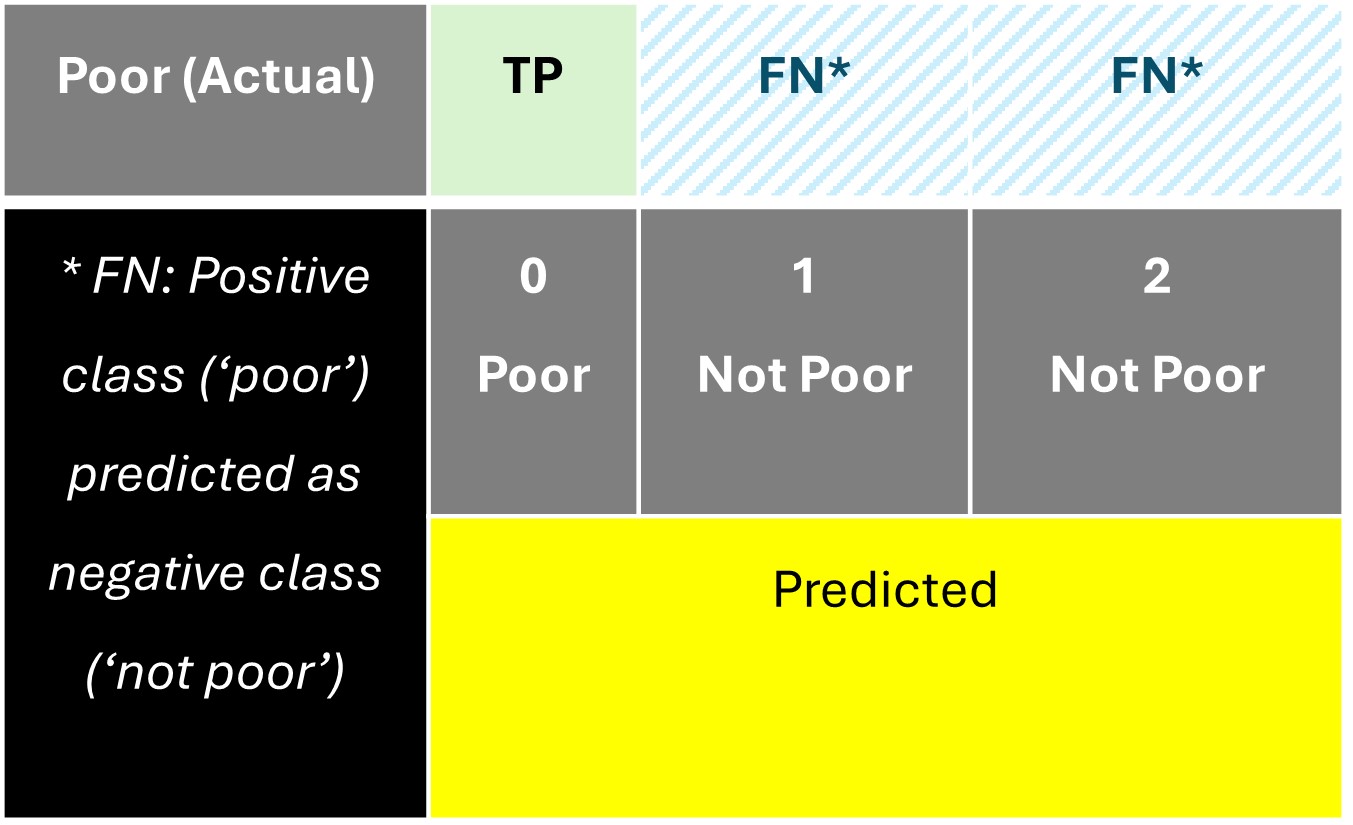
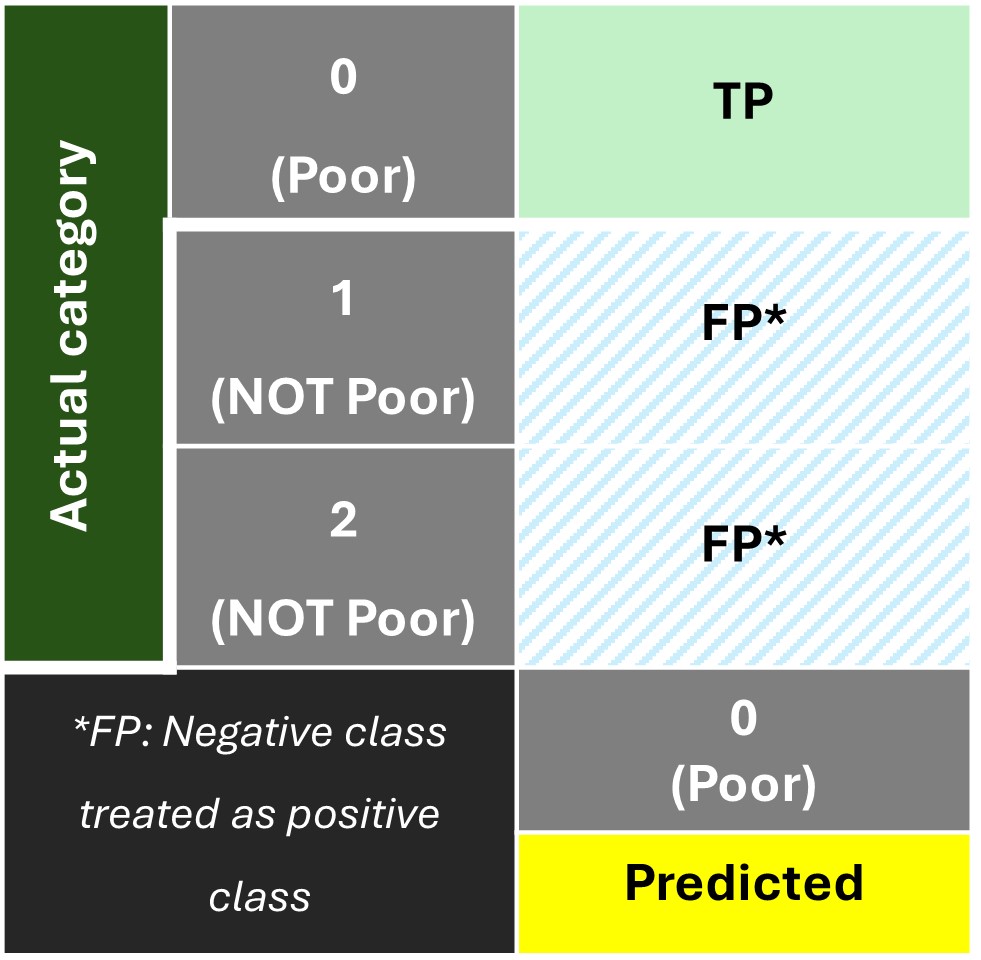
The remaining cells in the matrix are designated as 'True Negative' since both the actual and predicted class belong to the negative class 'NOT Poor'.
In a similar way, we can interpret the confusion matrices (shown below) for the categories 'Fair' and 'Excellent'.
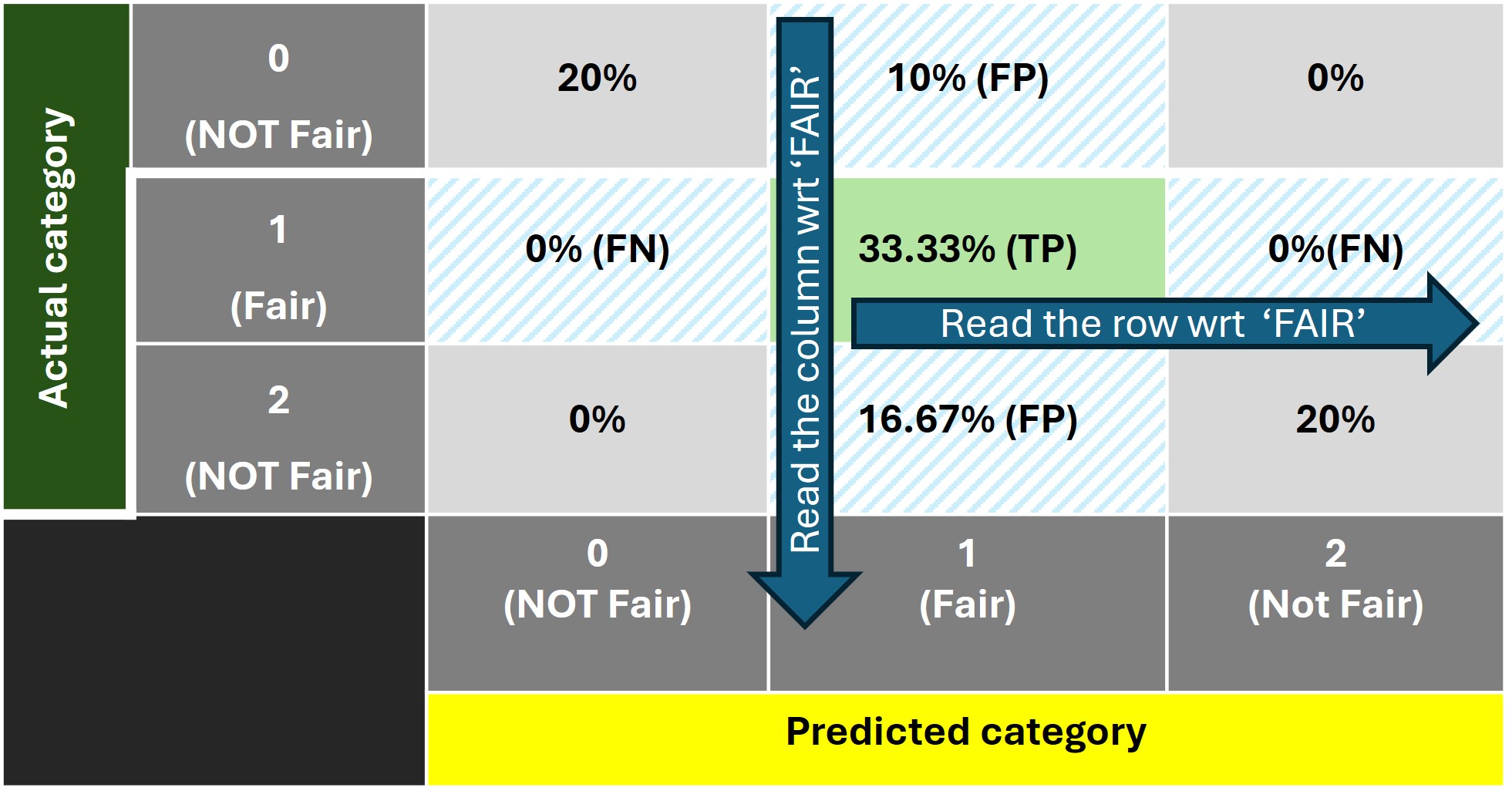
Now that we are clear with the interpretation of a multi-class confusion matrix, let's dive into calculating the 'accuracy' score, which tells us how well our model is performing.
Accuracy and Confusion Matrix